В чем я вижу ценность протоколов идентификации ТИМа
Очень кратко. Есть теоретическая модель А, которая описывает самые значимые свойства функций информационного метаболизма – ее параметры. Каждая функция обладает уникальным набором из трех параметров: размерность, знак и витальность/ментальность. Есть методика, которая детально описывает, как находить в речи типируемого эти параметры функций.
Делаем следующий шаг: берем речь типируемого и по данной методике находим аспекты информации и параметры функций.
Наблюдаем результат. Если информации достаточно по каждой функции, если теория была верна, то:
1. Все функции поделятся на две части: половина маломерные (2 рац и 2 иррац), половина многомерные (2 рац и 2 иррац).
2. Все функции поделятся на две части: половина витальные, половина ментальные. При этом каждый макроаспект разделится (если белая функция в ментале, то черная – в витале).
3. Все функции поделятся на две части по знакам (белые с одним знаком, черные с другим).
Согласитесь, довольно сложная комбинация, которая должна получиться в результате.
Если подобное деление повторяется раз за разом в десяти, двадцати, пятидесяти, ста запротоколированных анализах, разве это не подтверждает то, что модель А отражает действительность верно?
Каждый протокол содержит от 300 до 800 проанализированных фрагментов. Это не пара высказываний и поверхностные выводы, а избыточный материал для того, чтобы убедиться в правильности определения параметров.
Любой человек может перепроверить анализ, так как вся информация о методике анализа и сами протоколы имеются в открытом доступе на сайте ШСС.
В протоколах специально введена цветовая индикация. Если сложно углубляться в анализ текста, то можно просто просмотреть распределение цветов (по размерности функций).
Кроме того можно просмотреть каждый протокол через программу «Информационный анализ» (ИА), в которой есть возможность делать выборку по каждому параметру, а также увидеть систему переводов. Это тоже показательно.
Например:
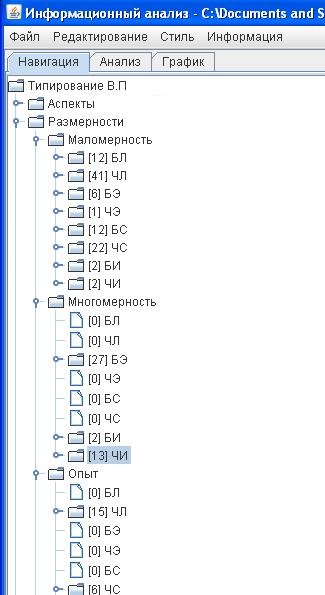
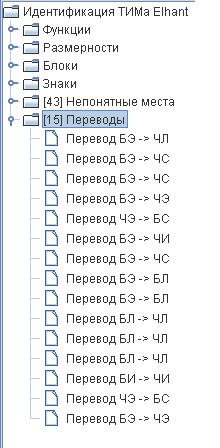
Эти же закономерности распределения можно проследить в итоговых таблицах, которые генерирует программа ИА в протоколе:
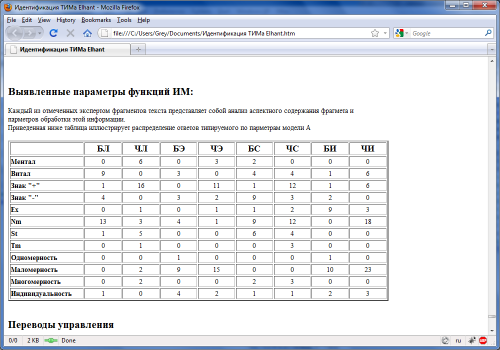
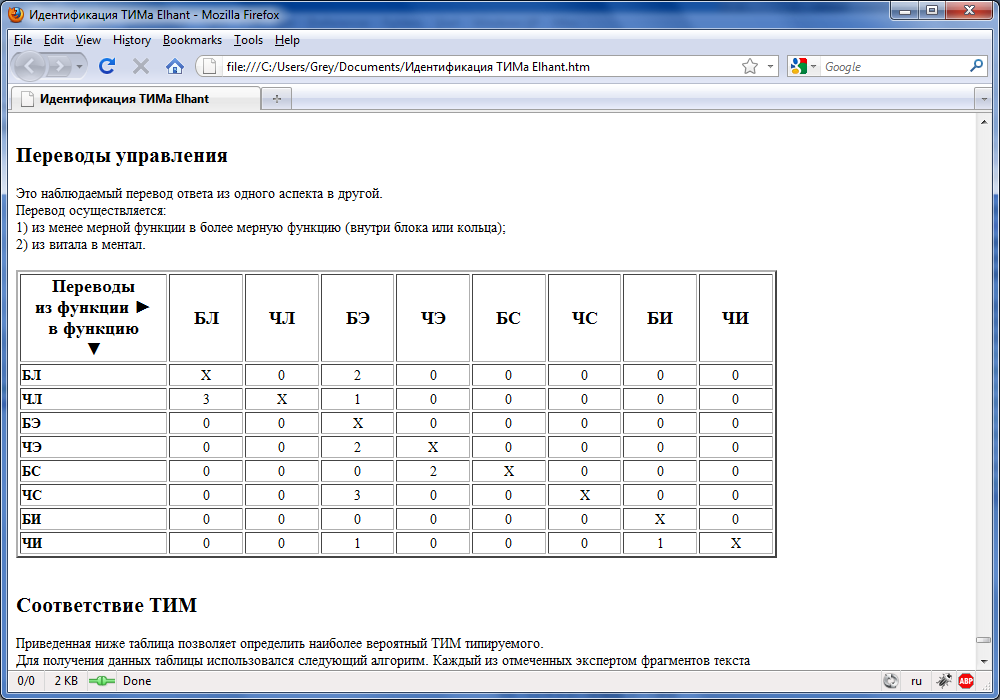
Вопрос: мы наблюдаем закономерности в обработке информации или совпадения?
Кто-то считает, что такого количества протоколов недостаточно для определенных выводов. Нужны тысячи? Когда-то их будет столько. Это только начало. Но это задокументированный факт наличия определенной структуры обработки информации, которая соответствует теоретической модели А.
Эглит И.М.